Whisper on Cloudflare AI
综合介绍
Whisper on Cloudflare AI 是一个极简的在线音频转写工具,它将强大的功能封装在一个单独的 worker.js 文件中。这个项目的核心特点是部署极其简单:用户只需将该文件的代码复制到Cloudflare Worker中,即可拥有一个私有的、高性能的语音转文字服务。它后端调用Cloudflare AI的@cf/openai/whisper-large-v3-turbo模型,前端则是一个功能完备的网页界面,用户可以直接上传音频文件,将其转录为文本或生成SRT字幕。该项目完美地展示了Cloudflare Serverless架构的便捷性,让不具备后端开发经验的用户也能轻松部署和使用先进的AI模型。
功能列表
- 极简一部署:整个项目只有一个
worker.js文件,无需复杂配置,复制粘贴代码即可完成部署。 - 独立Web应用:代码内建一个完整的网页界面,包含文件上传、参数选择、进度条显示和结果下载等功能,无需依赖任何外部网页。
- 先进的识别模型:明确使用Cloudflare AI提供的
@cf/openai/whisper-large-v3-turbo模型,确保了高准确率和高性能。 - 双重结果输出:提供
/raw接口返回原始JSON数据(包含每个片段的详细信息),以及/srt接口返回标准SRT字幕文件。 - 丰富的参数选项:支持
transcribe(转写)和translate(翻译)任务,并允许用户自定义语言、初始提示词(prompt)等高级参数。 - 纯前端处理字幕生成:从前端JavaScript代码可见,SRT字幕的生成是在用户的浏览器中完成的,减轻了服务器的负担,响应更快。
使用帮助
这个项目最吸引人的地方就是部署和使用的便捷性。以下是详细的操作指南。
第一步:如何部署自己的版本(核心步骤)
你只需要一个Cloudflare账户,即可在几分钟内部署这个工具。
- 登录Cloudflare账户:访问Cloudflare官网并登录。
- 进入Workers & Pages:在仪表盘左侧菜单中,点击
Workers & Pages。 - 创建新的Worker:
- 点击
Create application按钮。 - 选择
Create Worker选项。 - 为你的Worker指定一个唯一的子域名(例如
my-whisper-tool),然后点击Deploy。
- 点击
- 粘贴代码:
- 部署成功后,点击
Edit code进入代码编辑器。 - 编辑器中会有一段默认的示例代码,将其全部删除。
- 将本文档开头提供的完整
worker.js代码复制并粘贴到编辑器中。
- 部署成功后,点击
- 保存并部署:
- 点击右上角的
Save and deploy按钮。 - Cloudflare会自动为你完成部署。稍等片刻,你的在线音频转写工具就可以通过
https://你的子域名.你的workers.dev访问了。 - Cloudflare会自动为代码中使用的
env.AI绑定所需的AI模型,通常无需手动配置。
- 点击右上角的
第二步:使用你部署好的在线工具
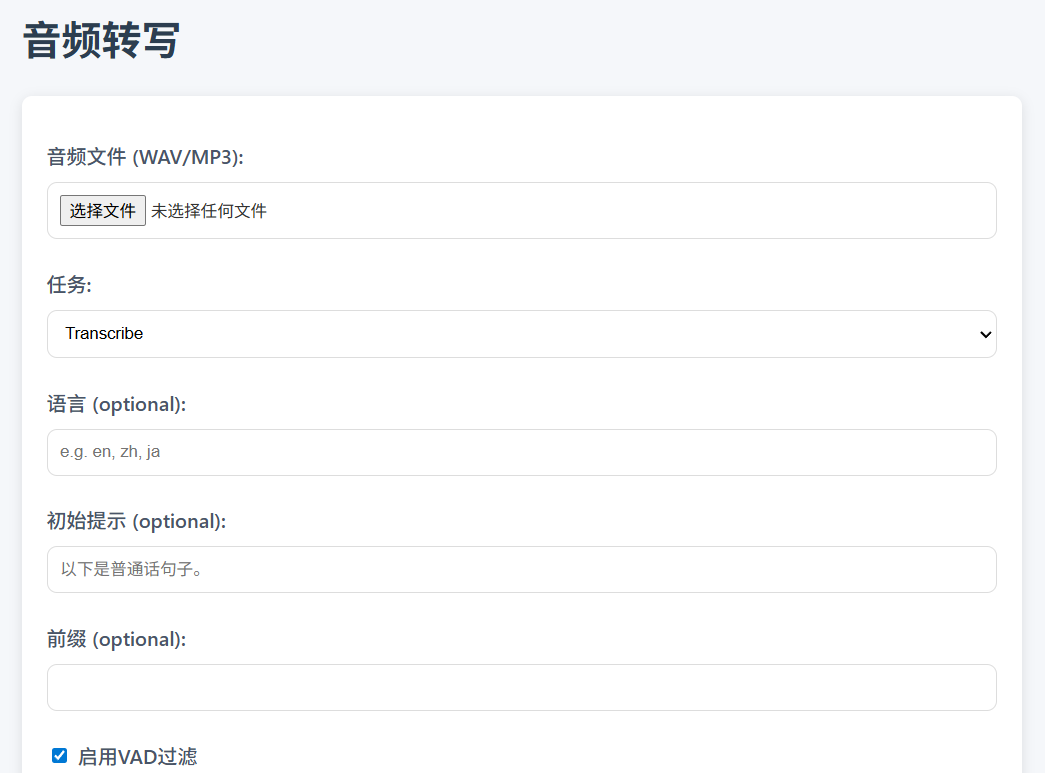
部署完成后,访问你的Worker URL,即可看到一个功能齐全的网页。
- 上传文件:点击“音频文件”区域选择一个本地的音频文件。
- 选择参数:
- 任务:选择“Transcribe”(转写成原文)或“Translate”(翻译成英文)。
- 语言:可以留空让模型自动检测,或输入语言代码(如
zh、en)来指定语言。 - 初始提示/前缀:输入一些特定术语或背景信息,可以帮助模型提高在特定领域的准确率。
- 启用VAD过滤:默认勾选,该功能可以过滤掉音频中的无声片段。
- 提交处理:点击“提交”按钮,文件将上传并开始处理,页面上会显示处理进度条。
- 查看和下载结果:处理完成后,SRT格式的结果会显示在文本框中。你可以直接点击“下载SRT”按钮,将结果保存为一个与你上传文件同名的
.srt字幕文件。
第三步:通过API接口调用(开发者选项)
你的Worker同样是一个API服务器。你可以通过POST请求与它交互。
- 请求端点:
https://你的子域名.你的workers.dev/raw或/srt - 请求方法:
POST - 请求头:
Content-Type: application/octet-stream - 请求体:音频文件的二进制数据。
- 查询参数:所有在网页上看到的选项(
task,language等)都可以作为URL查询参数附加到请求链接上。
cURL示例:
# 请求SRT格式结果
curl -X POST "https://my-whisper-tool.username.workers.dev/srt?language=zh" \
--header "Content-Type: application/octet-stream" \
--data-binary "@./myaudio.mp3" > subtitles.srt
# 请求原始JSON数据
curl -X POST "https://my-whisper-tool.username.workers.dev/raw" \
--header "Content-Type: application/octet-stream" \
--data-binary "@./myaudio.mp3"
应用场景
- 快速原型开发开发者可以利用这个项目快速搭建一个具备语音识别功能的演示应用,无需关心复杂的后端和模型部署,专注于核心业务逻辑的实现。
- 个人效率工具学生、记者或研究人员可以部署一个完全私有的实例,用于转录课程录音、采访内容和研究资料,确保数据隐私。
- 教育与学习教师可以指导学生如何通过简单的复制粘贴代码来部署一个先进的AI应用,直观地展示Serverless和AI模型的强大能力,降低学习门槛。
- 字幕自动化流程对于有自动化需求的用户,可以调用部署好的API接口,将其集成到脚本或工作流中,实现音频文件上传后自动生成字幕并保存到指定位置。
QA
- 如何部署自己的版本?只需三步:在Cloudflare创建一个新的Worker,将官方提供的
worker.js代码完整复制并粘贴进去,然后点击“Save and Deploy”即可。整个过程不需要任何编程知识。 - 这个项目使用的是哪个具体的Whisper模型?代码中明确指定了
@cf/openai/whisper-large-v3-turbo模型。这是Cloudflare AI提供的、基于OpenAI最新模型之一进行优化的版本,具有高性能和高精度的特点。 - 为什么我处理长音频时会失败?这通常是由于Cloudflare Workers的免费套餐对单次请求的CPU运行时间有限制。如果音频文件过长或处理过程过于复杂,可能会超出限制而中断。官方建议是,如果遇到错误,重试即可。
- 这个工具可以离线使用吗?不可以。它是一个网络工具,其核心计算(AI模型推理)发生在Cloudflare的服务器上,因此你的设备必须能够连接互联网才能使用。